- 11 fév.
Match ChatGPT ou Google? Ce que révèle une étude d'Oxford de 2026....
Une étude randomisée publiée dans Nature Medicine teste pour la première fois l'efficacité réelle de ChatGPT (et les autres) comme assistants médicaux pour le grand public. Les résultats remettent sérieusement en question leur utilisation actuelle.
J'en parle dans cette vidéo :
Ce que tu vas découvrir :
Le design de l'étude et ses résultats
Pourquoi ça ne fonctionne pas comme prévu
Ce que ça change pour ta pratique
La méthodologie
Les participants : 1 298 personnes non malades, représentatives de la population britannique
Le protocole : 4 groupes comparés
3 groupes avec assistance IA (GPT-4o, Llama 3, Command R+)
1 groupe contrôle avec les méthodes habituelles (Google, sites de santé)
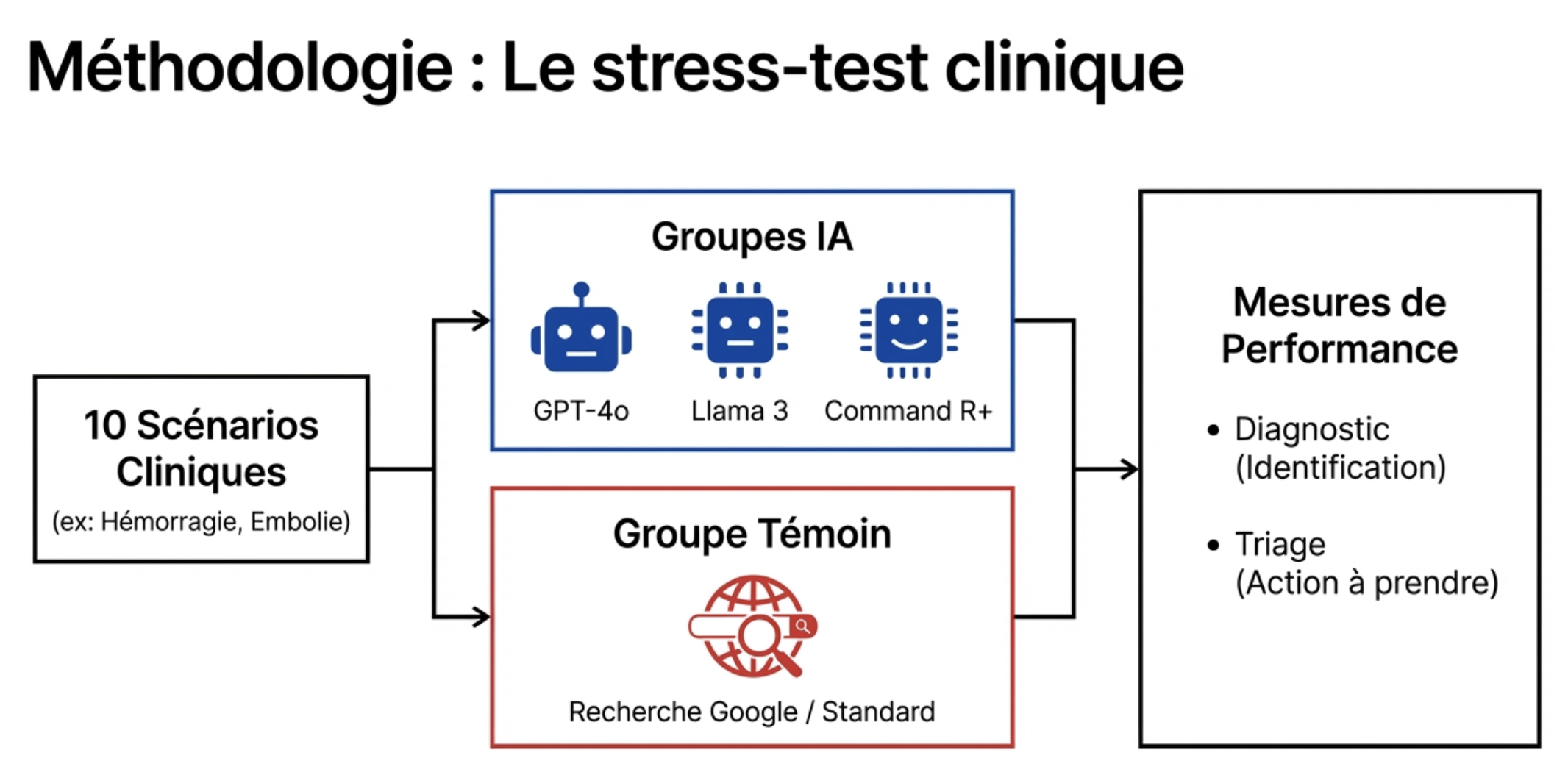
La mission : Chaque participant reçoit un scénario médical fictif (10 scénarios au total). Il doit :
Identifier le diagnostic probable
Décider de la conduite à tenir (de "je gère seul" à "j'appelle une ambulance")
Les scénarios : Créés et validés par 7 médecins, couvrant différentes situations (pneumonie, calculs biliaires, hémorragie cérébrale, rhume...)
Les résultats : un paradoxe troublant
Quand les IA travaillent seules
Les chercheurs ont d'abord testé les LLMs sans utilisateur humain :
✅ 95% de réussite pour identifier les bonnes conditions médicales
✅ 56% de réussite pour recommander la bonne conduite
Pas mal du tout ! Les IA ont clairement la connaissance médicale.
Quand des vrais gens utilisent les IA
Mais voilà ce qui se passe avec de vrais utilisateurs :
❌ Moins de 35% identifient les bonnes conditions (vs 55% pour le groupe contrôle)
-
❌ 44% choisissent la bonne conduite (vs 43% pour le groupe contrôle)
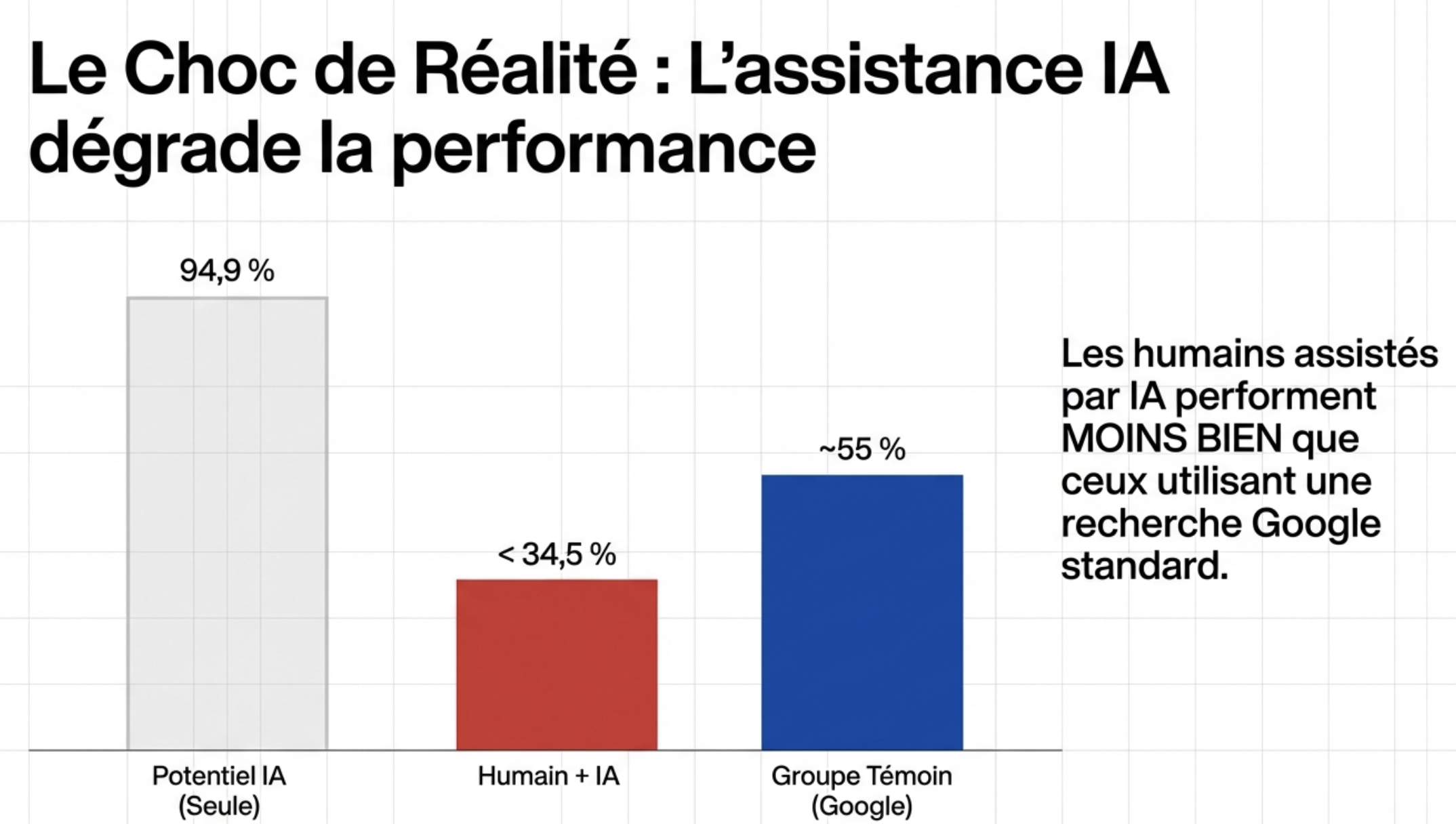
Le verdict : Utiliser ChatGPT ne t'aide pas plus que Google. Pire, pour identifier les conditions, tu fais moins bien.
Pourquoi ça échoue : 3 raisons identifiées
1. Les infos données sont incomplètes
Dans plus de la moitié des conversations analysées, les participants ne donnent pas assez de détails dès le départ.
Exemple concret :
Un participant avec un scénario de calculs biliaires écrit : "J'ai des douleurs d'estomac qui me font vomir."
→ Il oublie de préciser : la localisation exacte, l'intensité, le lien avec les repas gras
Résultat : le LLM suggère dyspepsie et reflux gastrique, mais rate les calculs biliaires.
2. Trop d'options, mauvais tri
Les LLMs proposent en moyenne 2,2 diagnostics possibles par conversation. Problème : seulement 1 sur 3 est pertinent.
Le participant se retrouve face à une liste : méningite, migraine, sinusite... Et devine quoi ? Il choisit souvent la mauvaise. Même quand la bonne réponse apparaît dans la discussion, elle ne finit pas toujours dans sa conclusion.
C'est comme donner un formulaire médical complexe à quelqu'un sans formation : il coche les mauvaises cases.
3. Les réponses sont imprévisibles
Détail inquiétant : deux participants décrivent des symptômes quasi identiques d'hémorragie cérébrale au même LLM.
Participant 1 : "Repose-toi dans une pièce sombre"
Participant 2 : "Va aux urgences immédiatement"
Une petite différence de formulation → recommandation radicalement opposée. Le patient n'a aucun moyen de savoir s'il a posé la "bonne" question.
Le chiffre à retenir (et à partager avec tes patients)
Dans plus d'un cas sur 2 (entre 56% et 75% selon les modèles), ChatGPT n'aide ni au diagnostic ni à l'orientation.
Autrement dit : utiliser un LLM comme ChatGPT pour s'autodiagnostiquer, c'est presque jouer à pile ou face. Avec un risque supplémentaire : l'illusion de compétence. Le patient pense avoir fait une recherche "intelligente", alors qu'il a souvent juste obtenu une réponse plausible mais fausse.
Les LLMs excellent dans les examens médicaux (60-80% de réussite), mais échouent avec de vrais patients (35-44% de réussite). Le problème n'est donc pas la connaissance, mais l'interaction.
En pratique pour toi
La bonne nouvelle ? Ton expertise reste irremplaçable. L'étude le confirme : même les meilleurs LLMs ne remplacent pas un interrogatoire médical structuré.
La mauvaise ? Tu vas devoir déconstruire des conclusions erronées avant même de commencer ton vrai travail diagnostique. Prépare-toi à recevoir des patients convaincus d'avoir une méningite parce que ChatGPT l'a suggéré (spoiler : c'est souvent une migraine).
Et toi?
As-tu déjà eu des consultations compliquées par un autodiagnostic IA ? Comment as-tu géré la situation ?
Source : Bean et al. (2026), "Reliability of LLMs as medical assistants for the general public: a randomized preregistered study", Nature Medicine